ToasterNet: The Bot Back End Organizing Santa Collab

Several years back, we created this Santa Collab game. The final result ended up being a collaboration between 17 artists.

You can check it out and play the game on the Game's Page, but this post isn't about the game itself.
Behind the scenes, there was a bot created to organize all: Enter ToasterNet!
This post is about the technical aspect of what went on behind the scenes to organize it.
ToasterNet
ToasterNet was a bot created to facilitate and organize the Santa Collab.

Here is the diagram of how ToasterNet is setup on the back end. This will be shown again as a whole and with certain parts highlighted as needed.
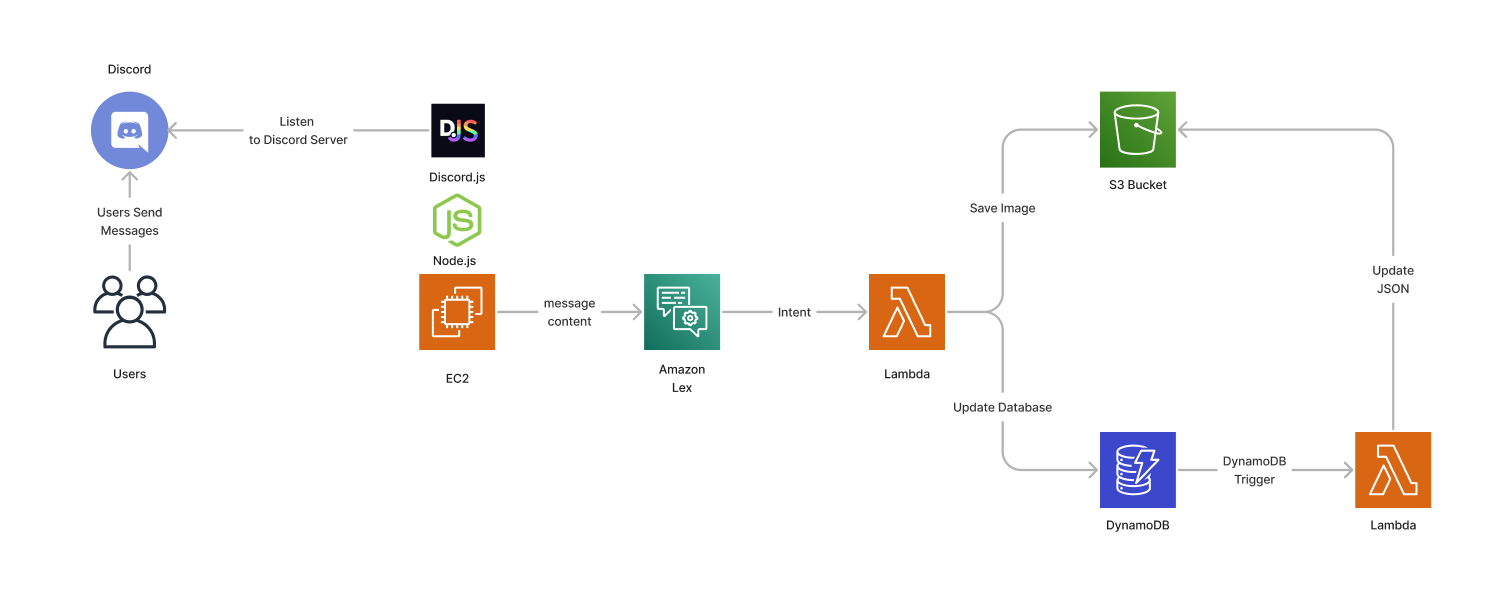
Note: response to the user is omitted. As it can happen at various stages, I didn't want to clutter the diagram with all those arrows going back to Discord.
Why ToasterNet?
Here is the one-liner (run on sentence?) of the benefit of setting this up:
Instead of manually adding every artists' art to the project and waiting until assembled to view it, the artists submit art via ToasterNet which not only saves and tracks their files which automatically get added to the project, ToasterNet will let them know what else they need to do, provide a url to preview their current art in the game, and notify them of any issues with their assets, for example, the assets being the wrong dimensions.
Most similar collabs have admins helping everyone out, answering questions, and then assembling everything after the due date. Each of the ToasterNet commands would instead be a question or request an admin would need to follow up on.
Front-End
This post will focus on the back-end setup, but I want to briefly overview the front end. Some of the decisions on how to set up the back end were influenced by the structure of the front end.
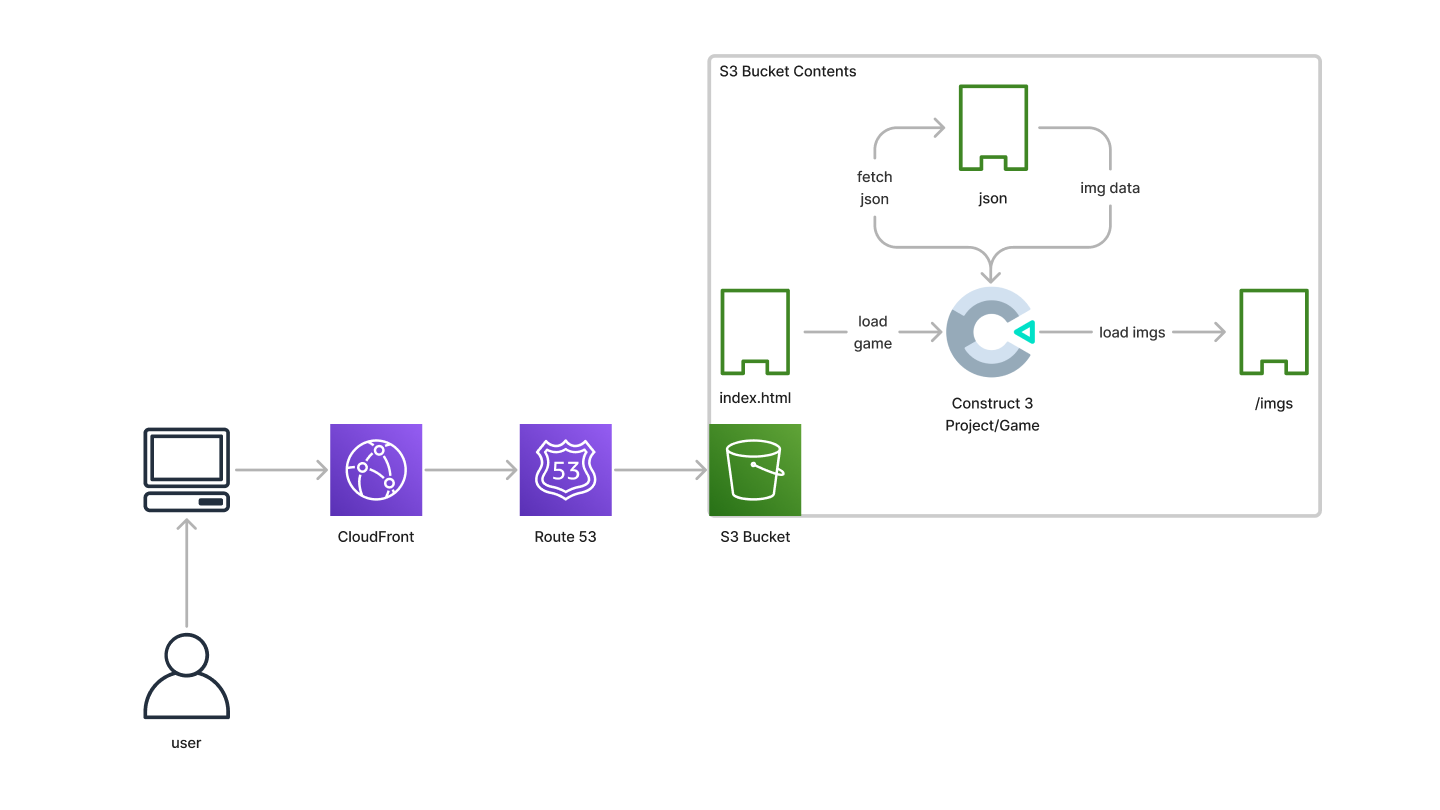
S3 Bucket Host
The website is hosted in an S3 Bucket. If interested, you can check out this AWS Tutorial for more details. Note that CloudFront and Route 53 are part of components of setting up an S3 hosted website.
The critical aspect is that S3 Hosted websites are static and do not have back-ends. That means if you are working with a database, you don't have anywhere to put server-side code that you can obscure away.
Construct Project
Construct 3 is an HTML5 game engine. Therefore, exporting it for the web runs like a typical web page consisting of HTML, CSS, and JavaScript.
Nothing special needs to be done for the game to run. Simply upload the files, and the game can be loaded in an iframe, or the game page can navigated to itself.
Files
This S3 Bucket also contains the JSON file and images created/saved by ToasterNet.
Note that this is the same S3 Bucket as the one in the Back End diagram.
Front End Flow
- User navigates to website
- Construct Project loads (aka, the game)
- JSON file fetched
- The JSON file contains the data on which artists completed all the assets, therefore, how many worlds exist and which images to load for each.
- After navigating to a level (in-game), images are loaded from the paths listed in the JSON
Back to the backend!
Back End
We will start on the left.
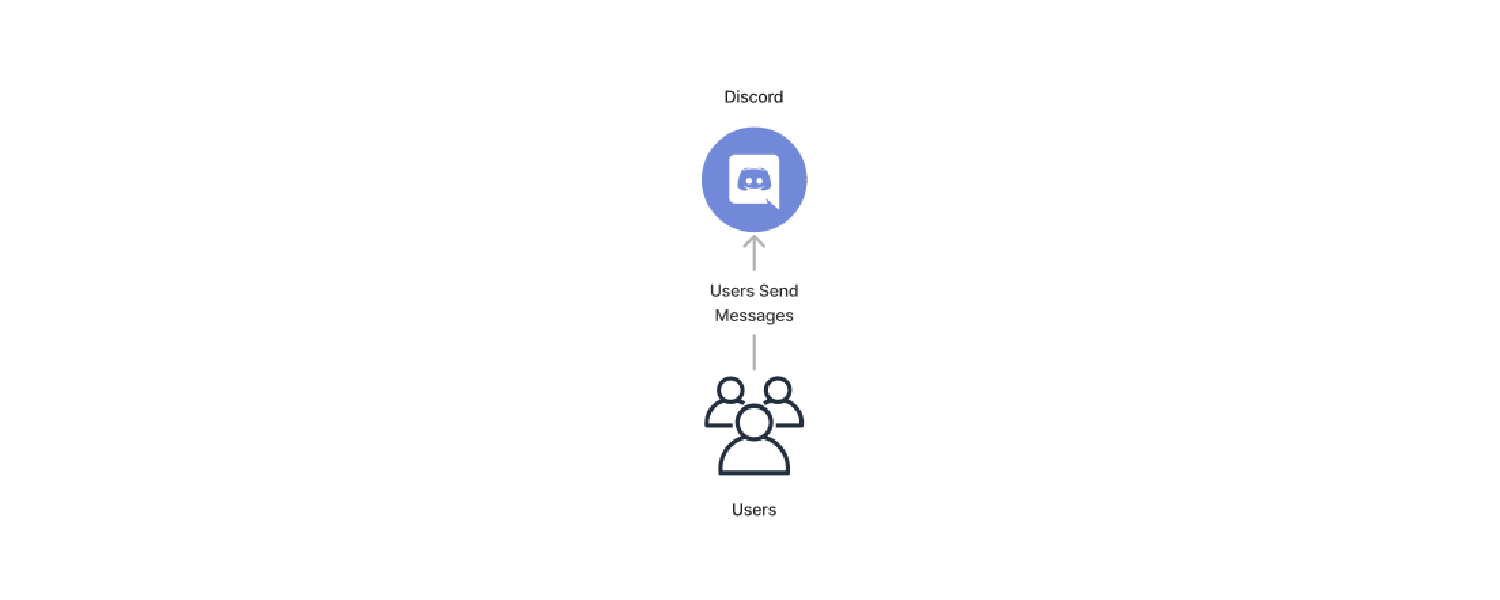
Discord
Two reasons for using a Discord Server:
- CubeCollabs already had a Discord server where everyone was active.
- No need to deal with user managment!
No need exists for anyone to log in anywhere else, create a new account, deal with password resets, etc. Everyone participating was already logged into Discord, and the Discord Bot can use their Discord ID to identify them uniquely.
I created the bot in Discord Developer Portal and added it to our server.
We created a channel on our server specifically for this collab and instructed people to ping the bot when they wanted to interact with it. This prevented the bot from responding to every single message or not responding if it needed clarification on what you were asking.
Note: This was before bot intents were a feature in Discord
EC2 Server
An EC2 Server Instance was created running node.js, and Discord.JS was installed.
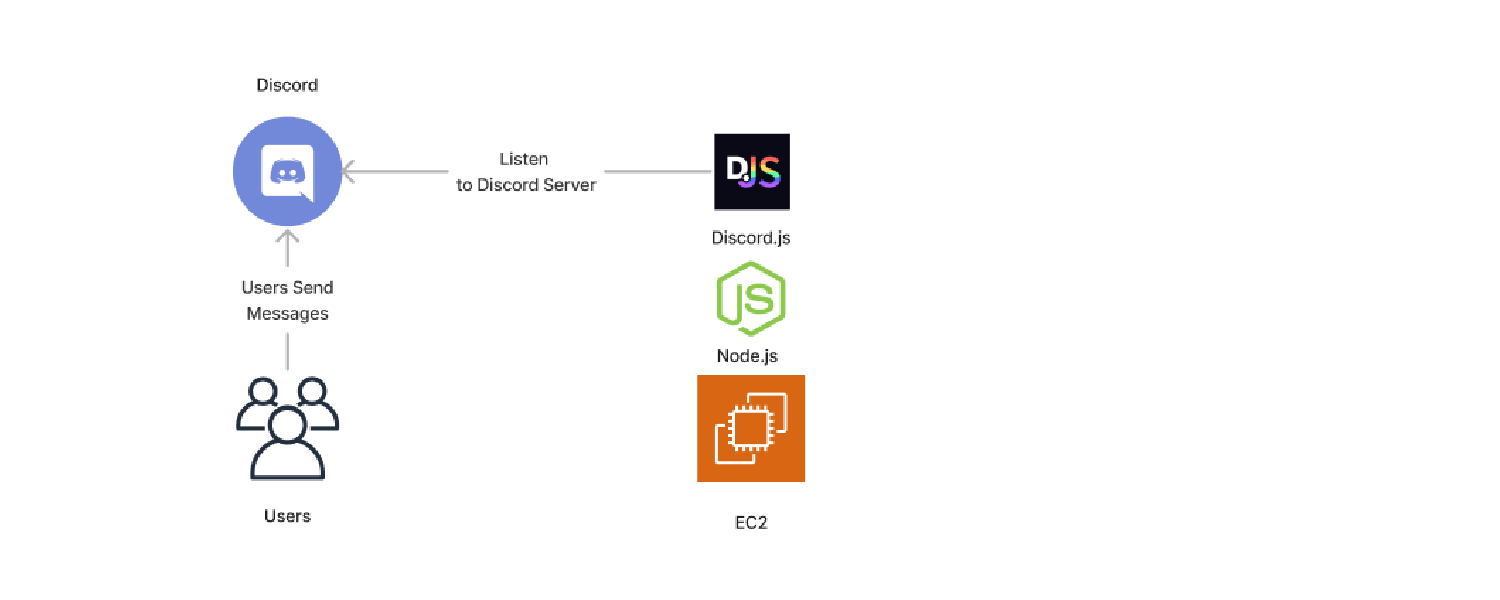
Using the Discord SDK, set up a listener on the server. This is triggered by every message. Therefore, filters are set up to only continue if in the correct channel, ToasterNet is pinged, and the message is not from ToasterNet itself.
Amazon Lex
The message is sent to Amazon Lex for any message that passes the filters.
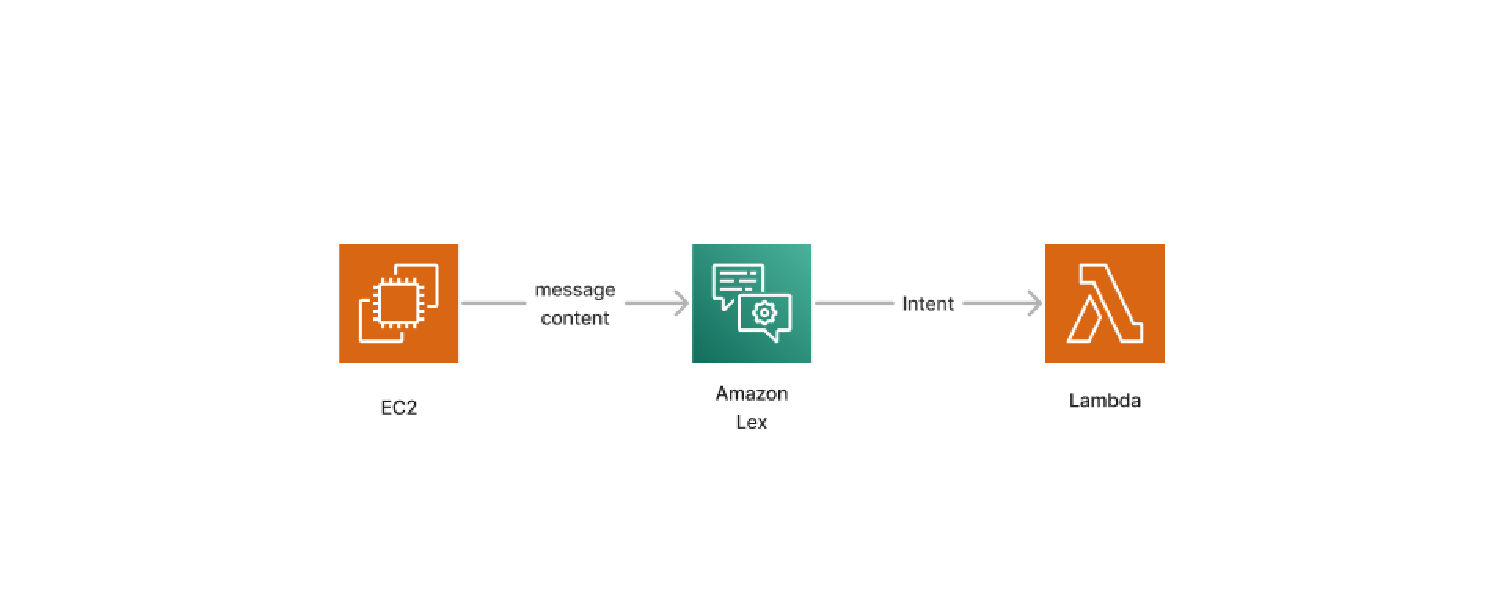
In my own words, Lex is a machine learning platform that takes the text and matches it to an intent. The intents need to be set up by the developer with example phrases and synonymous words. Once done, any synonymous term should still be matched to the intent.
The benefit is that the user does not need to memorize specific commands.
Also, with a few different intents we set up to guide the user, they try asking it any question they had on their mind. Of course, this doesn't respond to the questions like ChatGPT, but you'd be surprised how many questions could be fulfilled by a handful of helpful prompts.
Lambda
Amazon Lex can integrate a different Lambda for each intent. The flowchart is based on the intent for uploading art assets.
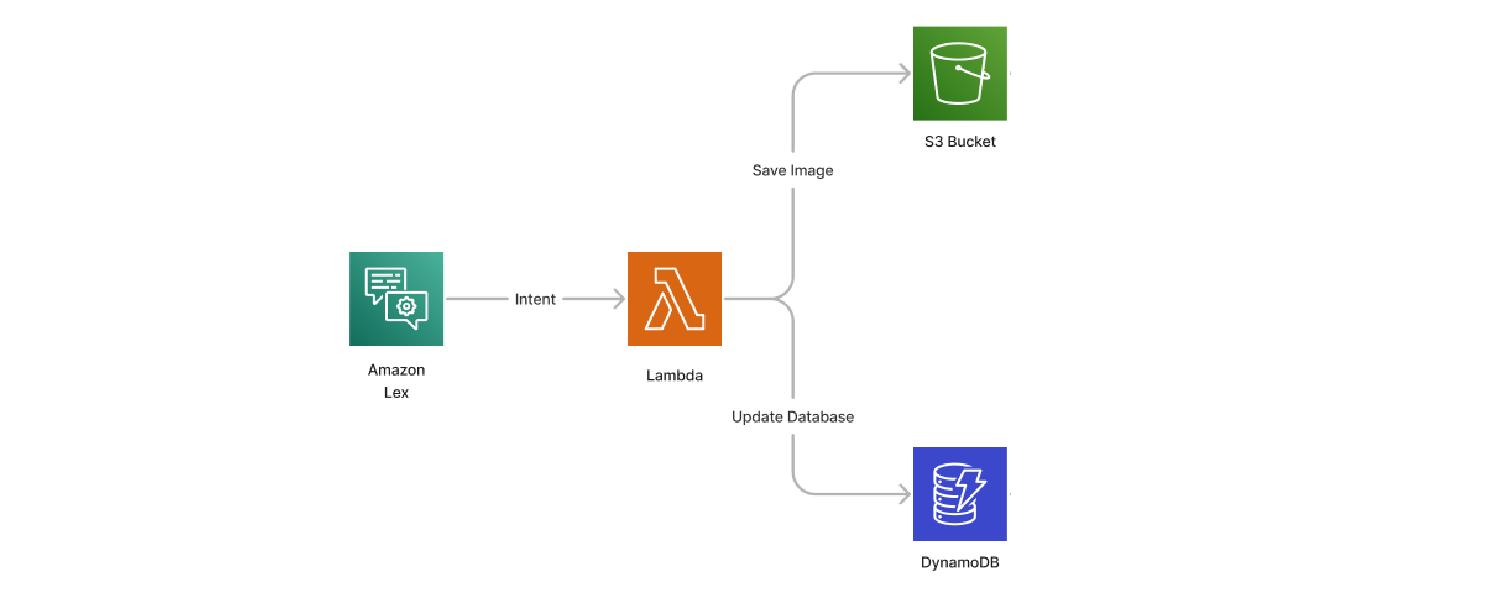
This Lambda has two steps:
- Upload the image to the S3 bucket
- Update DynamoDB with the path and filename
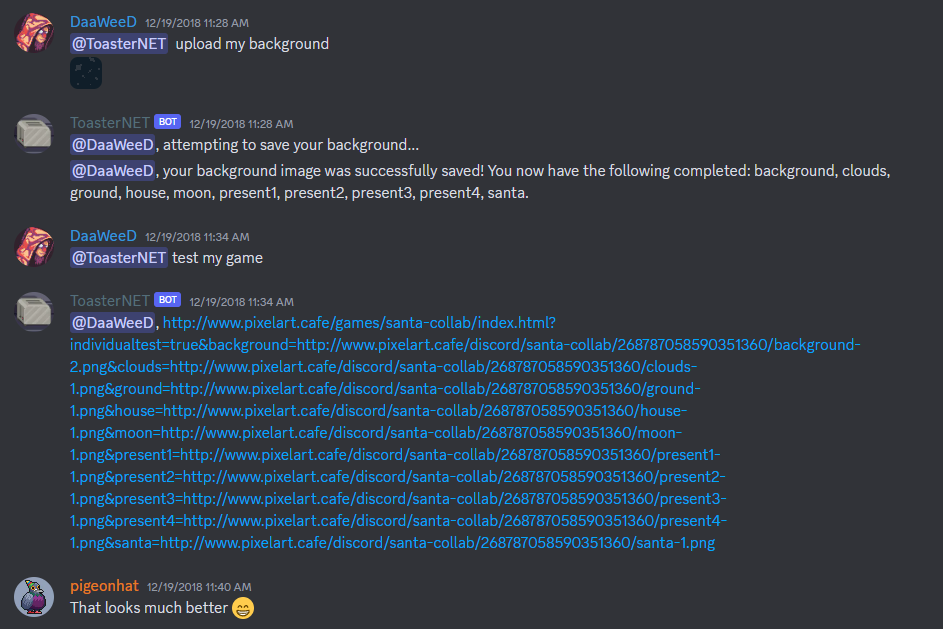
Here is an example of what that looks like to the user:
You can see the success message that the art assets completed are listed. This is created after receiving the Return Value from the Dynamo Update.
Hindsight on Microservices
The goal at the time was to utilize Lambdas as microservices. The server would function to simply filter and route messages to the appropriate microservice. Actually, Lex was doing the routing.
In hindsight, if I did it again, I'd probably have Lex return the intent to the server. That way I could keep all the logic on the server instead of spreading it amongst microservices.
It was nice not having to restart the application on the server when updating one Lambda function. And I did re-use some of the microservice Lambdas in later projects. But I'd say the benefits of having all the code on the EC2 server - organization and reusability - would be more convenient than the microservices approach.
S3 Bucket
The Lambda would take the image provided in the message and save it to the S3 bucket.
Note that the S3 bucket was the same S3 bucket used for the front end. The S3 Bucket was set up for hosting, which, again, has no CORS issues to navigate when the game attempts to load each asset.
The Lambda does wait for a successful response to the create file request before proceeding to update DynamoDB.
DynamoDB
Once the asset is saved, DynamoDB is updated to mark that asset as complete and keep the path.

The screenshot above shows the urls of the assets uploaded by PixelShorts, though demonstrates a different intent: test my game. The artist is provided a preview link that has query params for all the art they have completed thus far. The project will use those query params to load their art so they can see it in action. This can be done at any stage, even before they have finished all their art assets.
Remember that we use Discord for user management and authentication. Upon receiving a message, the Discord ID is in the original object from discord.js and is passed along in every step. The key for the NoSQL database is the discord ID.
Lambda Trigger
Upon DynamoDB being updated, a lambda is triggered to scan the database, format the data, and place a json file in the S3 Bucket.
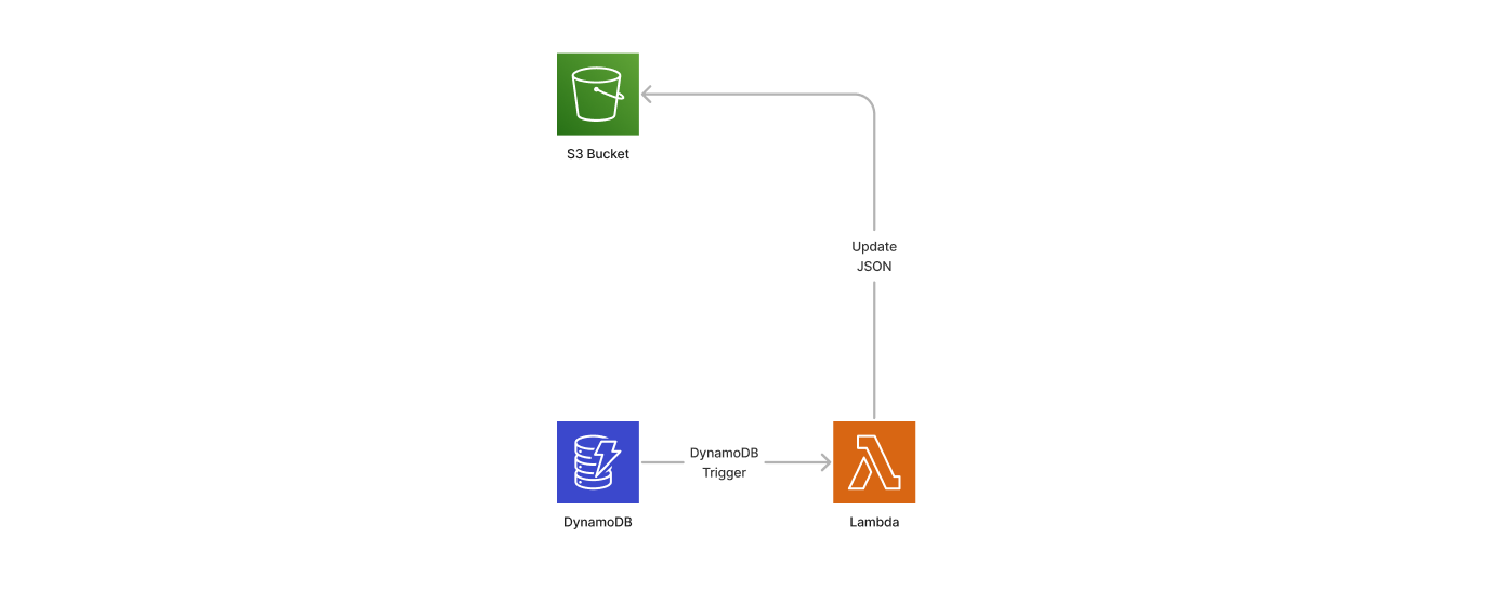
The Lambda formats the JSON in a way that is easier for me to parse in Construct, and filters out some information that is in the database but not needed in the game.
Redundant JSON?
I have thought it seems kind of redundant to implement a step of creating a JSON file from a NoSQL database.
Though, S3 Hosted Websites do not have a backend. Therefore, to query DynamoDB from the front end, we need to set up an API Gateway endpoint with a Lambda to query the database. Though I've done this numerous times, for example with my high scores tables, simply fetching a json file actually seems to the simpler route.
Once again, this S3 Bucket we are storing the JSON file in is the same bucket as the game is hosted, so there are no CORS issues.
Back End Recap
To recap, below is the diagram again, here is a quick recap:
- User Sends Message in Discord "@ToasterNet, here is my Santa art"
- EC2 Server: message passes filters and is sent to Amazon Lex
- Lex: Intent is determined that user wants to save Santa Asset. Corresponding Lambda triggered.
- Lambda:
- Lambda saves image from Discord to S3 Bucket
- After succes, Lambda Updates DynamoDB, recording asset path
- Lambda responds to user in Discord
- DynamoDB being updated triggers a Lambda. Lambda scans database, formats for Construct, and saves the JSON file to the S3 Bucket
More Interaction Screenshots
Here are a few more screenshots of people interacting with ToaterNet and other commands or responses.
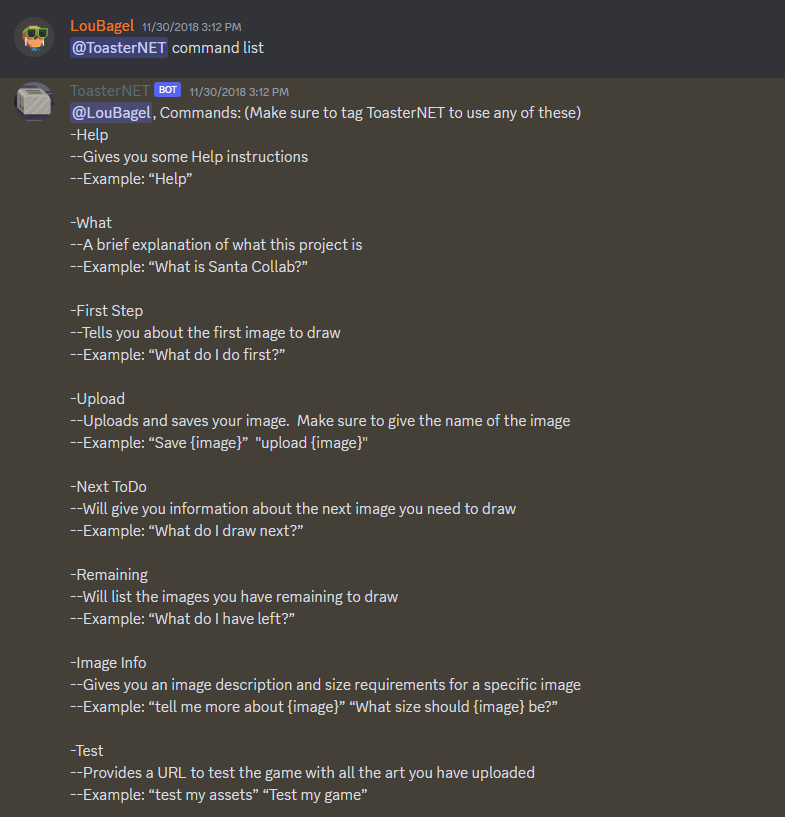
First, here is a help menu with some of the commands:
Here is another example of an artist's workflow with ToasterNet:
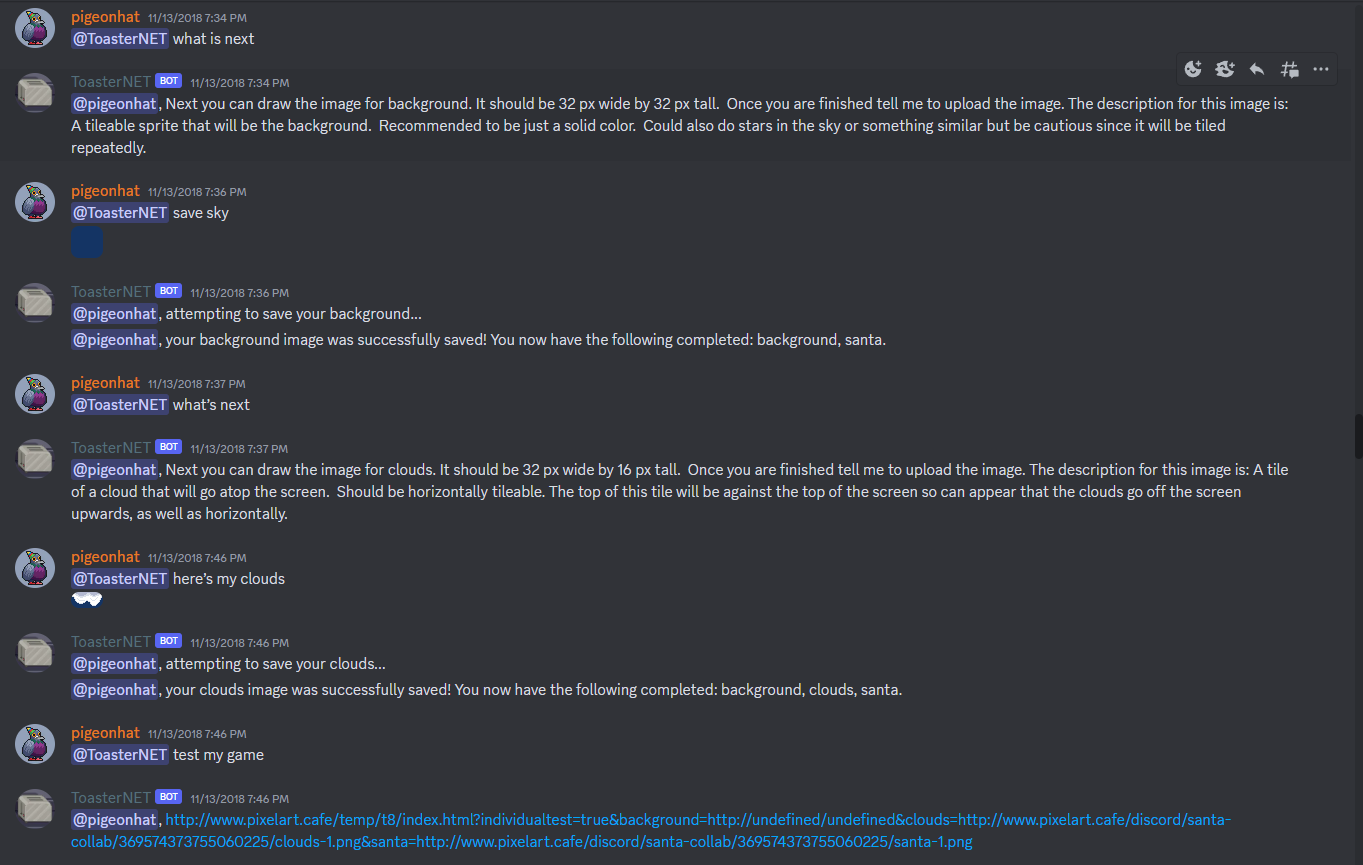
They used the following commands:
- What is Next?
- Save Asset
- What is Next?
- Save Asset
- Test my game
And now for something completely random . . .
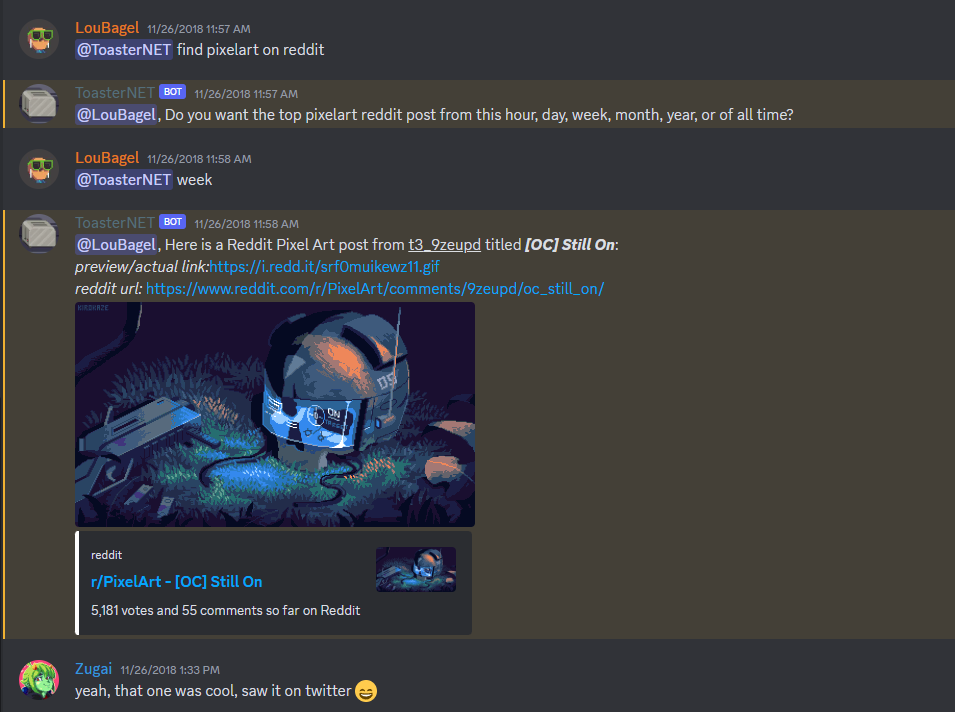
The nice thing with microservices, since I was messing around with Reddit APIs for something else, I could easily use the same Lambda to add the functionality for ToasterNet. To be clear, this did not serve any useful purpose.
Last but not least, here is what happens when you are finished:
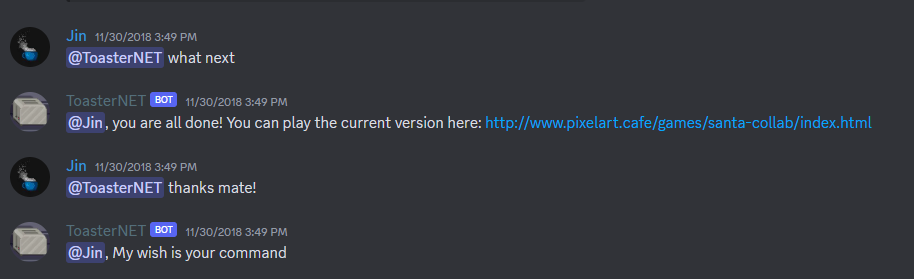
I'll leave you with this . . .



Comments?
Below are links to where this post is shared on each social media
Instead of a comment section on the blog, I invite you to bring the comments to your social media of choice!